Learning with Less Labeling (LwLL)

This is an ongoing project. The details are subject to change.
The following project description is taken from DARPA.
In supervised machine learning (ML), the ML system learns by example to recognize things, such as objects in images or speech. Humans provide these examples to ML systems during their training in the form of labeled data. With enough labeled data, we can generally build accurate pattern recognition models.
The problem is that training accurate models currently requires lots of labeled data. For tasks like machine translation, speech recognition or object recognition, deep neural networks (DNNs) have emerged as the state of the art, due to the superior accuracy they can achieve. To gain this advantage over other techniques, however, DNN models need more data, typically requiring 109 or 1010 labeled training examples to achieve good performance.
The commercial world has harvested and created large sets of labeled data for training models. These datasets are often created via crowdsourcing: a cheap and efficient way to create labeled data. Unfortunately, crowdsourcing techniques are often not possible for proprietary or sensitive data. Creating data sets for these sorts of problems can result in 100x higher costs and 50x longer time to label.
To make matters worse, machine learning models are brittle, in that their performance can degrade severely with small changes in their operating environment. For instance, the performance of computer vision systems degrades when data is collected from a new sensor and new collection viewpoints. Similarly, dialog and text understanding systems are very sensitive to changes in formality and register. As a result, additional labels are needed after initial training to adapt these models to new environments and data collection conditions. For many problems, the labeled data required to adapt models to new environments approaches the amount required to train a new model from scratch.
The Learning with Less Labeling (LwLL) program aims to make the process of training machine learning models more efficient by reducing the amount of labeled data required to build a model by six or more orders of magnitude, and by reducing the amount of data needed to adapt models to new environments to tens to hundreds of labeled examples.
LwLL Evaluation
The evaluation has 3 types of tasks: Image Classification, Object Detection and Machine Translation. Our team is focusing on the image classification task. Each task includes a base phase and an adaptation pha where each phase consists of 6 to 8 stages. For image classification, pre-trained models on predefined whitelisted datasets are allowed.
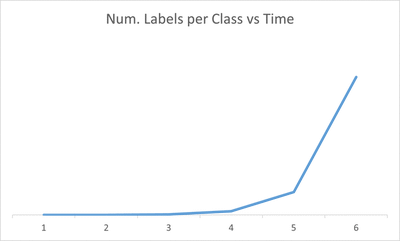
The full training set without any label is given at the beginning. At stage 1, can request 1 label per category in the training set (label budget is 1). As the training progress, the label budget is increased.
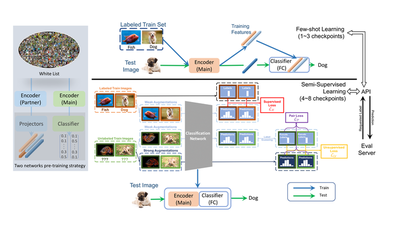
Our team used a few-shot learning method for the first 2 to 3 checkpoints when the labeled set size is small. Once sufficient number of labeled data samples become available, the training was handed to our semi-supervised algorithm.
SimPLE: Similar Pseudo Label Exploitation for Semi-Supervised Classification
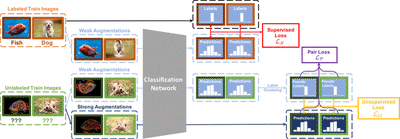
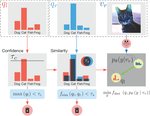
We proposed a novel semi-supervised classification algorithm, SimPLE (Figure 3), that focuses on the less studied relationship between the high confidence unlabeled data that are similar to each other.
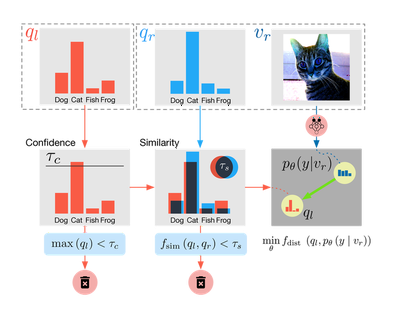
As shown in Figure 4, the new proposed Pair Loss minimizes the statistical distance between high confidence pseudo labels with similarity above a certain threshold. The similarity threshold “extended” our confidence threshold in an adaptive manner, as a sample whose pseudo label confidence is below the threshold can still be selected by the loss and be pushed to a higher confidence level.
Formally, we defined the Pair Loss as the following:
$$
\begin{aligned}
\mathcal{L_P} &= \frac{1}{\binom{KB}{2}}
\sum_{\mathcal{U}'}
\mathbb{1}_{\max\left(q_l\right) > \tau_c} \cdot
\mathbb{1}_{f_{\operatorname{sim}}\left(q_l,q_r\right) > \tau_s} \\
&\cdot f_{\operatorname{dist}}\left(q_l, \mathrm{p}_{\text{model}}\left(\tilde{y} \mid v_r ; \theta\right)\right)
\end{aligned}
$$
Notations:
- $K$: number of augmentations
- $B$: batch size
- $\mathcal{U}'$: unlabeled batch
- $\tau_c$: confidence threshold
- $\tau_s$: similarity threshold
- $f_{\operatorname{sim}}\left(\cdot,\cdot\right)$: similarity function
- We use Bhattacharyya coefficient.
- $f_{\operatorname{dist}}\left(\cdot,\cdot\right)$: distance function
- We use $1-$ Bhattacharyya coefficient.
Experimental Results
| Dataset | Num. Labels | Method | Backbone | Top-1 Accuracy |
|---|---|---|---|---|
| CIFAR-100 | 10000 | MixMatch | WRN 28-8 | 71.69% |
| ReMixMatch | WRN 28-8 | 76.97% | ||
| FixMatch | WRN 28-8 | 77.40% | ||
| SimPLE | WRN 28-8 | 78.11% | ||
| Mini-ImageNet | 4000 | MixMatch | WRN 28-2 | 55.47% |
| MixMatch Enhanced | WRN 28-2 | 60.50% | ||
| SimPLE | WRN 28-2 | 66.55% | ||
| ImageNet to DomainNet-Real | 3795 | MixMatch | ResNet-50 | 35.34% |
| MixMatch Enhanced | ResNet-50 | 35.16% | ||
| SimPLE | ResNet-50 | 50.90% | ||
| DomainNet-Real to Mini-ImageNet | 4000 | MixMatch | WRN 28-2 | 53.39% |
| MixMatch Enhanced | WRN 28-2 | 55.75% | ||
| SimPLE | WRN 28-2 | 58.73% |
Our algorithm, SimPLE, achieved state-of-the-art performance on standard SSL benchmarks and achieved the best accuracy on some tasks in LwLL evaluation. We also evaluated our method in the transfer setting where our algorithm outperforms prior works and supervised baseline by a large margin.
Development Detail
- Designed a novel algorithm for semi-supervised classification
- Evaluated our algorithm on standard benchmarks (CIFAR-10, CIFAR-100, SVHN, Mini-ImageNet)
- Evaluated our algorithm in the transfer learning setting (on Mini-ImageNet, DomainNet-Real, AID, RESISC45), where models are initialized models pretrained on ImageNet or DomainNet-Real
- Distributed training with PyTorch Distributed Data Parallel
- GPU accelerated data augmentation with Kornia
Related Publications
Zijian Hu
Machine Learning Research Engineer
My research interests include computer vision, machine learning, natural language processing, and robotics.